Algorithmes
I- Recherche par dichotomie⚓︎
Cliquez sur Fiche dichotomie.pdf pour récupérer l'énoncé du TD.
1) Akinator⚓︎
Enoncé
Vous jouez à essayer de deviner le nombre auquel pense votre adversaire : en début de partie, celui-ci pense à un nombre entre 0 et 100, le note sur une feuille qu’il retourne (pour éviter la triche). Vous devez trouver ce nombre en un minimum de propositions. L’adversaire ne peut dire que "c’est plus", "c’est moins" et "bravo".
- Essayez de décrire votre stratégie.
- En justifiant votre réponse, indiquez quel serait le nombre minimum de questions à poser afin de trouver le résultat de façon sûre et certaine.
- Écrire une fonction akinator(n) qui va chercher à deviner le nombre x auquel vous pensez (0 ≤ x ≤ n) en utilisant la même stratégie que vous.
Corrigé
La meilleure méthode est de diviser systématiquement l'intervalle en deux et de prendre le milieu.
Si par exemple le nombre à trouver est 37, commencer par demander 50 ("c'est moins"), puis 25 ("c'est plus"), puis 37 ("Bravo !").
On se rend compte qu'on a une démarche binaire : comme il est possible de coder 128 nombres sur 7 bits, il est possible de deviner n'importe quel nombre en 7 questions.
def akinator(n):
mini=0
maxi=n
while (maxi-mini)>1 :
milieu=(maxi+mini)//2
print("Est-ce qu’il s’agit de :",milieu,"?")
reponse=input("Répondre par \"+\" ou \"-\" ou \"oui\"")
if reponse=="+":
mini=milieu
elif reponse=="-":
maxi=milieu
else:
return True
2) Encadrer la solution d'une équation de type f(x)=0⚓︎
Enoncé
La fonction f(x)=x3-1,45x2-11,55x+5,39 admet une solution s telle que f(s)=0 avec 0 ≤ s ≤ 1
On donne
def f(x):return x**3-1.45*x**2-11.55*x+5.39
- Proposer une adaptation de l’algorithme akinator pour trouver une valeur de s arrondie à 10-3 près.
Corrigé
def f(x):return x**3-1.45*x**2-11.55*x+5.39
def resolv(fonction,mini,maxi,intervalle):
while (maxi-mini)>intervalle :
milieu=(maxi+mini)/2
if fonction(maxi)*fonction(milieu)>0:
maxi=milieu
elif fonction(maxi)*fonction(milieu)<0:
mini=milieu
else:
return milieu
return mini,maxi
La partie la plus compliquée de l'algorithme est mathématique : comment écrire un équivalent de "c'est plus" ou "c'est moins" ?
Il se trouve que si la fonction est strictement monotone et qu'elle admet une solution dans un intervalle, alors les 2 extrêmités de cet intervalle n'ont pas le même signe => f(mini)×f(maxi)<0.
On teste donc f(maxi)×f(milieu). Si la valeur est positive, c'est que la solution se trouve entre mini et milieu et donc que notre nouvel intervalle est [mini;milieu].
3) Rechercher une valeur dans une liste ordonnée par dichotomie⚓︎
Enoncé
Une liste de nombres est générée par la commande
liste=[randint(0,10)]
for i in range(1,100000) :
liste.append(liste[i-1]+randint(1,10))
On souhaite rechercher si un nombre est présent dans cette liste le plus rapidement possible.
- D’après ce code, la liste est-elle déjà ordonnée ? Si oui, en ordre croissant ou décroissant ?
- Est-il possible que la liste contienne deux fois le même nombre ?
- Écrire une fonction recherche_dicho(nombre,liste) qui recherche par dichotomie le nombre dans liste et retourne si elle le trouve son indice et si elle ne le trouve pas les 2 indices encadrant la position qu’il aurait dû avoir
- Utiliser le benchmark de la séance algorithmes01 pour vérifier si cette méthode est réellement plus rapide que l’algorithme indice(liste,valeur) écrit précédemment.
Attention : votre fonction bench génère par défaut une liste aléatoire, ce qui n’est pas le cas de la liste ci-dessus, modifiez la fonction en conséquence !
Corrigé
- On voit que chaque terme est égal au terme précédent augmenté de randint(1,10). Cette liste est donc ordonnée en ordre strictement croissant.
- répondu juste au-dessus
- A vous de chercher !
- A vous de chercher !
II- Algorithmes gloutons⚓︎
Cliquez sur Fiche algo glouton pour récupérer l'énoncé du TD.
1) Introduction⚓︎
Il y a certains problèmes problèmes pour lesquels il existent un très grand nombre de solutions. Parmi ces solutions quelques unes sont optimales, mais l'écrasante majorité ne le sont pas. Il n'est dans certains cas pas possible de trouver une solution optimale car cela demanderait un nombre de calculs hors de portée ou trop coûteux par rapport aux moyens à disposition.
Dans ce cas, il peut être intéressant de disposer d'un algorithme qui, s'il ne donne pas la solution optimale, est tout du moins capable de trouver une solution, de préférence pas trop mauvaise.
Ce genre d'approche, on l'a déjà abordée au moins une fois : pour faire sortir le robot du labyrinthe : en gardant toujours le mur à droite, on s'assure de pouvoir sortir, mais on ne trouvera généralement pas le trajet le plus court vers la sortie.
Les algorithmes gloutons répondent à cette problématique
En choissant systématiquement l'option qui les rapproche le plus de l'objectif, ils permettent de trouver une solution qui si elle n'est pas systématiquement optimale est généralement satisfaisante.
2) Problème du rendu de monnaie⚓︎
Enoncé
Caisse automatique

Vous êtes employé par l’entreprise CashExpress, spécialisée dans la vente de caisses enregistreuses automatiques : pour éviter les contacts entre les employés et la clientèle, le client dépose directement l’argent dans un automate qui se charge de lui rendre la monnaie.
On suppose que la monnaie peut-être rendue avec toutes les pièces et billets existant en euros :
[200, 100, 50, 20, 10, 5, 2, 1, 0.5, 0.2, 0.1, 0.05, 0.01]
(En effet, les billets de 500€ ne sont plus produits depuis 2018)
- Un client vous présente un billet de 50€ pour payer sa chocolatine a 0,85€, indiquez le détail du rendu de monnaie que vous allez faire.
Un algorithme évident afin de rendre systématiquement correctement la monnaie, serait de rendre uniquement des pièces de 1 cent.
Cela présente 2 inconvénients majeurs :- il est nécessaire de prévoir un très gros volume de pièce de 1 cent afin de pouvoir continuer à rendre la monnaie tout au long de la journée
- Vous risquez d’irriter vos clients
- Proposez une stratégie vous permettant systématiquement de rendre la monnaie en utilisant un nombre minimal de pièces/billets.
- Écrire la fonction rendu_monnaie(montant) qui retourne un dictionnaire contenant le détail du rendu de monnaie pour un montant donné.
Exemple : Le client a payé sa baguette à 1,05€ avec un billet de 5€ → l’automate doit lui rendre 3,95€
rendu_monnaie(3,95) → {'200':0, '100':0, '50':0, '20':0, '10':0, '5':0, '2':1, '1':1, '0.5':1, '0.2':2, '0.1':0, '0.05':1, '0.01':0}
Une boulangerie basée en Absurdistan souhaite se procurer une de vos machine. Leur monnaie est le Plouk, dont le taux de change est proche de l’Euro : 1 Pk = 1 €.
Leur monnaie est différemment échelonnée : [200, 100, 30, 20, 5, 2, 1, 0.3, 0.1, 0.05, 0.01]
- En adaptant la fonction rendu_monnaie(montant) aux différentes valeurs disponibles dans ce pays, quel retour propose-t-elle pour 45 Pk ?
Ce rendu est-il optimal ?
Corrigé
- Je dois lui rendre 50 - 0.85 = 49.15€
Le meilleur rendu est 2×20€, 1×5€, 2×2€, 1×0.10€, 1×0.05€. - Pour rendre le moins de monnaie possible, il faut toujours rendre la plus grande valeur possible.
- c.
monnaie=[200,100,50,20,10,5,2,1,0.5,0.2,0.1,0.05,0.02,0.01]
def rendu_monnaie(montant,monnaie):
rendu={}
montant=int(100*montant)
for piece in monnaie:
if montant>=100*piece:
rendu[piece]=int(montant//(piece*100))
montant-=rendu[piece]*(piece*100)
return rendu
Il faut faire attention à la façon dont Python travaille sur les nombres flottants.
Pour éviter un problème, il faut s'assurer que les nombres sont entiers en les mutipliant par 100.
- Une fois le programme ci-dessus écrit de cette façon, il suffit d'ajouter une nouvelle liste pour les pièces en Plouks.
monnaie_Pk=[200, 100, 30, 20, 5, 2, 1, 0.3, 0.1, 0.05, 0.01]
On lance ensuite
>>> rendu_monnaie(45,monnaie_Pk)
{30: 1, 5: 3}
L'algorithme propose alors de rendre 4 devises, tandis que la solution optimale était de 3 : 2×20Pk, 1×5Pk.
3) Les fractions égyptiennes⚓︎
Si les égyptiens ne connaissaient pas la notation décimale, ils connaissaient les fractions, sous une forme particulière (voir Wikipédia ) : leurs fractions étaient de la forme où . On parle de fraction unitaire.
Ils pouvaient donc écrire n’importe quel nombre rationnel (un nombre qui peut s’écrire comme le quotient de 2 nombres entiers) en le décomposant d’une infinité de façons à l’aide de fractions unitaires.
Par exemple .
Cette solution les satisfaisait probablement d’autant plus qu’il n’est pas sûr qu’ils savaient que certains nombres ne pouvaient être rationnels, comme √2 ou π!
Enoncé
Il vous faudrait écrire un algorithme glouton egypte(nombre) qui décompose n’importe quel nombre 0<x<1 en somme de fractions unitaires…
Bien sûr, du fait des spécificités de la prise en charge des nombres et le fait que certains nombre se décomposent nécessairement en une somme infinie de fractions, il faudra accepter une approximation de cette décomposition.
Corrigé
def egypte(nombre,epsilon=1e-7):
n=2
sortie=""
while nombre>epsilon:
if 1/n<=nombre:
nombre-=1/n
sortie+="+1/"+str(n)
n+=1
return sortie[1:]</pre>
L'algorithme est "simple" : il part de la fraction 1/2 puis comme dans le problème du rendu de monnaie, regarde s'il peut retrancher la fraction à la valeur à décomposer. Le cas échéant, il ajoute son écriture à la décomposition. Il continue jusqu'à ce que le reste soit inférieur à une valeur de référence facultative epsilon.
>>> egypte(2/3)
'1/2+1/7+1/43+1/1807+1/3263443'
Remarque
Cette façon de décomposer un nombre décimal devrait vous rappeler quelque chose, puisque c’est de cette façon que l’on détermine l’écriture binaire d’un décimal, en utilisant des fractions unitaires de la forme .
4) Le voleur⚓︎
Il s'agit d'un grand classique de l'algorithme glouton, vous le retrouverez facilement sur Internet
Marcel Lupin est un voleur prévoyant. Avant de perpétrer ses larcins, il prend soin de lister les objets de valeur présents chez ses futures malheureuses victimes. Il n’emporte sur les lieux qu’un seul sac de 50kg, il doit être sélectif !
Il établit donc une liste (enfin, nous dirions plutôt dictionnaire, mais Marcel n’est pas informaticien) des objets présents, en indiquant tout d’abord leur masse en kg puis leur valeur en Brouzoufs (c’est la monnaie d’Andorrsbourg, riche petite principauté voisine de l’Absurdistan dans laquelle se déroule notre histoire).
Cette liste est disponible ci-dessous :
{'A': [4, 54], 'B': [2, 9], 'C': [14, 91], 'D': [14, 4], 'E': [8, 18], 'F': [1, 98], 'G': [5, 56], 'H': [15, 85], 'I': [7, 61], 'J': [3, 83], 'K': [2, 75], 'L': [10, 70], 'M': [7, 73], 'N': [14, 71], 'O': [7, 3], 'P': [6, 75], 'Q': [9, 91], 'R': [14, 16], 'S': [9, 48], 'T': [9, 37], 'U': [13, 83], 'V': [3, 30], 'W': [12, 81], 'X': [3, 72], 'Y': [2, 10], 'Z': [3, 24]}
Enoncé
Proposez une fonction a_voler(dictionnaire) qui pour un dictionnaire donné retourne la liste des items à voler en priorité afin d’avoir la plus grande valeur dans le sac.
→ Cette fonction calcule également la valeur du contenu du sac.
Corrigé
victime={'A': [4, 54], 'B': [2, 9], 'C': [14, 91], 'D': [14, 4], 'E': [8, 18], 'F': [1, 98], 'G': [5, 56], 'H': [15, 85], 'I': [7, 61], 'J': [3, 83], 'K': [2, 75], 'L': [10, 70], 'M': [7, 73], 'N': [14, 71], 'O': [7, 3], 'P': [6, 75], 'Q': [9, 91], 'R': [14, 16], 'S': [9, 48], 'T': [9, 37], 'U': [13, 83], 'V': [3, 30], 'W': [12, 81], 'X': [3, 72], 'Y': [2, 10], 'Z': [3, 24]}
"""
rech_max cherche la plus grande valeur d'un dictionnaire de listes
en permettant de choisir sur quel indice de la liste on fait la comparaison
"""
def rech_max(dictionnaire,indice):
cles=list(dictionnaire.keys())
max=dictionnaire[cles[0]][indice]
cle_max=cles[0]
for i in cles:
if dictionnaire[i][indice]>max:
max=dictionnaire[i][indice]
cle_max=i
return cle_max
"""
la fonction a_voler(dictionnaire,capacite_sac) fait 3 choses
- calcule la valeur/kg de chaque objet et l'ajoute au dictionnaire
- ajoute récursivement l'objet le plus rentable dans le dictionnaire 'sac',
à la condition que celui-ci puisse encore rentrer
- supprime cet objet dans le dictionnaire
"""
def a_voler(dictionnaire,capacite_sac):
sac={}
valeur=0
for i in dictionnaire.keys():
dictionnaire[i].append(dictionnaire[i][1]/dictionnaire[i][0])
while capacite_sac>0 and len(dictionnaire)>0:
cle_max=rech_max(dictionnaire,2)
if dictionnaire[cle_max][0]<=capacite_sac:
print("on ajoute",cle_max,dictionnaire[cle_max])
capacite_sac-=dictionnaire[cle_max][0]
sac[cle_max]=dictionnaire[cle_max]
valeur+=dictionnaire[cle_max][1]
del(dictionnaire[cle_max])
return valeur,sac
#lancer la fonction avec <strong>a_voler(victime,50)
#la fonction remplira un sac de 50kg avec les objets de victime
La principale difficulté de cet algorithme est de trouver à quel paramètre appliquer l'algorithme glouton ! Ce n'est pas forcément la valeur de l'objet, car celui-ci peut valoir beaucoup mais remplir le sac à lui seul.
Le paramètre de la valeur rapportée au kilogramme est plus judicieux, car il nous assure de maximiser le butin à chaque prise. En revanche, cet algorithme ne sera pas forcément optimal !
Je vous laisse chercher un exemple dans lequel ce ne sera pas le cas :)
III- Algorithme des k-plus proches voisins⚓︎
1) Intelligence Artificielle et détermination⚓︎
Un problème classique pour ce que l'on appelle "Intelligence Artificielle" est celui de la détermination : étant donné un objet, défini par une série de valeurs (taille, poids, valeur, durée, ... ) et (au moins) 2 groupes différents A et B aux caractéristiques différentes, on aimerait déterminer si l'objet appartient au groupe A ou au groupe B.
Les applications sont très larges :
- Le visage en photo est-il celui d'un homme ou d'une femme ?
- Le tableau est-il de Claude Monet ou d'Edouard Manet ?
- La balance connectée pèse-t-elle un adulte ou un enfant ?
Il existe beaucoup d'algorithmes permettant de réaliser cette tâche, nous allons étudier l'un des plus abordables, celui des k-plus proches voisins.
2) Principe⚓︎
Pour pouvoir déterminer l'appartenance d'un objet à un groupe, il faut à l'avance connaître les paramètres de chaque groupe. Seulement les données étant rarement complètes (et parfois les concepteurs sachant pas à l'avance quel sera le paramètre le plus judicieux), on donne plutôt un jeu de données contenant les paramètres de plusieurs objets auxquels un groupe a déjà été attribué (par un ensemble de spécialistes ou via les réponses aux Captchas que vous validez sur internet).
On compare ensuite pour chaque nouvel objets ses dimensions par rapport aux objets de chaque groupe et on détermine le groupe de cet objet comme étant celui dont il est le plus proche.
Il nous faut donc :
- Un ensemble d'objets ayant des mesures et appartenant à un groupe défini
- Un objet ayant des mesures et dont le groupe est à déterminer
- Déterminer comment on mesure la distance des objets entre eux
Voyons cela au travers de l'exemple le plus courant de cet algorithme :
3) Un problème de fleurs⚓︎
a. Présentation⚓︎
Saviez-vous qu'il existe plusieurs espèces d'iris ?
| Iris Setosa | Iris Virginica | Iris Versicolor |
|---|---|---|
 |
 |
 |
Quand on les regarde, on voit qu'effectivement, elles sont différentes, mais difficile de dire en quoi !
Heureusement, en 1936, Edgar Anderson a mesuré des caractéristiques des différentes espèces, et notamment :
| Fleur | Longueur et largeur d'un sépale | Longueur et largeur d'un pétale |
|---|---|---|
 |
 |
 |
b. Récupération et visualisation des données⚓︎
Le fichier iris.txt contient les dimensions des pétales de différentes fleurs ainsi que son espèce sous la forme
[longueur du pétale, largeur du pétale, groupe]
avec groupe : [0,1,2] → [setosa, versicolor, virginica].
liste_fleurs=[] #On crée une liste vide
with open("iris.txt","r",encoding="utf-8") as txt:
for ligne in txt:
liste_fleurs.append(eval(ligne[:-1]))
Si l'on trace rapidement un graphique par espèce avec la longueur du pétale en abscisses et sa largeur en ordonnée pour chaque fleur, on obtient le graphique suivant :
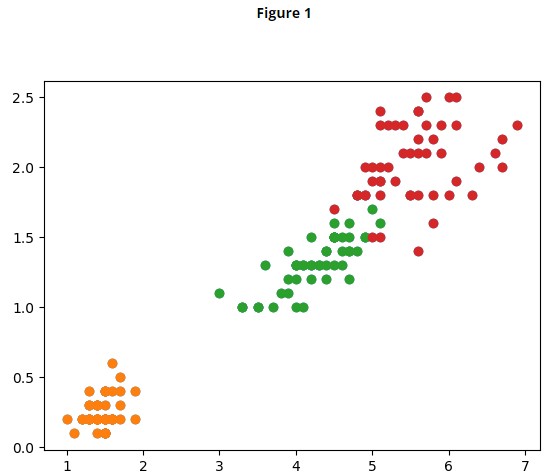
On voit maintenant clairement 3 groupes :
- en orange, les setosa sont clairement séparées des 2 autres espèces ;
- en vert les versicolor ;
- enfin les virginica, plus grandes, mais dans la continuité directe des versicolor
Ces groupes, faciles à identifier à l'oeil sont en fait le véritable enjeu de l'algorithme des k plus proches voisins.
c. Calculer les distances⚓︎
Imaginons maintenant que nous ayons 4 nouvelles fleurs définies par les dimensions de leurs pétales :
- A : [4,1.2]
- B : [1.5,0.4]
- C : [6.5,2.3]
- D : [5,1.7]
Les fleurs A, B et C sont faciles à placer sur le graphique ci-dessus, mais quid de D ?
Pour déterminer leur groupe d'appartenance, il va falloir calculer pour chaque fleur A,B,C,D la "distance" à laquelle elle se trouve de chaque fleur du groupe de données. Cette distance peut être déterminée de plusieurs façons, considérons pour ne pas nous compliquer la tâche, la distance euclidienne classique
\(AB=\sqrt{(x_B-x_A)^2+(y_B-y_A)^2}\)
def distance(xa,ya,xb,yb):
return ((xb-xa)**2+(yb-ya)**2)**0.5
def liste_distances(fleur_inconnue,liste):
distances=[]
for fleur in liste:
dist=distance(fleur_inconnue[0],fleur_inconnue[1],fleur[0],fleur[1])
distances.append([dist,fleur[2]])
return distances
La commande liste_distances([5,1.7],liste_fleurs) retournera donc une liste récapitulant la distance à laquelle se trouve la fleur D de chacune des fleurs présentes dans le fichier iris.txt.
d. Repérer les plus proches voisines⚓︎
Maintenant que l'on connait les distances à chaque fleur, on va devoir déterminer quelle est l'espèce la plus représentée parmi les plus proches voisines.
Il faut donc :
- Trier la liste retournée par liste_distances par ordre croissant
- Prendre les 5 premières fleurs et en recenser l'espèce
Pour le tri, le plus simple est de reprendre le tri par insertion :
def tri_selection(liste):
for i in range(len(liste)):
maxi=liste[0][0]
indice=0
for j in range(len(liste)-i):
if liste[j][0]>maxi:
maxi=liste[j][0]
indice=j
liste[indice],liste[len(liste)-i-1]=liste[len(liste)-i-1],liste[indice]
return liste
Parmi les k premiers éléments de cette liste on va recenser le nombre de fleurs de chaque espèce :
def plus_proches(liste,k=5):
especes=dict()
for i in liste[:5]:
if i[1] in especes.keys():
especes[i[1]]+=1
else :
especes[i[1]]=1
return especes
Finalement, il ne reste qu'à trouver l'espèce qui est la plus représentée
def recherche_cle_max(dictionnaire):
liste_cles=list(dictionnaire.keys())
cle_max=liste_cles[0]
maxi=dictionnaire[cle_max]
for i in liste_cles[1:]:
if dictionnaire[i]>maxi:
maxi=dictionnaire[i]
cle_max=i
return cle_max
Pour connaître l'espèce à laquelle appartient les fleurs A,B,C et D, il suffit donc de faire :
for i in [[4,1.2],[1.5,0.4],[6.5,2.3],[5,1.7]]:
print(recherche_cle_max(plus_proches(tri_selection(liste_distances(i,liste_fleurs)))))