les images numériques
I - Définition/diagonale/format/résolution⚓︎
La définition
Elle correspond au nombre de pixels que contient une image ou un écran. Elle est indiquée sous la forme
nombre_de_pixels_en_largeur × nombre_de_pixels_en_hauteur

Le format
Le format d'une image ou d'un écran correspond au rapport entre la largeur et la hauteur de l'image ou de l'écran.

Résolution
La résolution correspond à la "finesse" de l'image, c'est à dire au rapport au nombre de pixels par unité de longueur de l'image. Cette valeur dépend évidemment de la façon dont l'image doit être affichée, en revanche pour un écran, elle est fixe.
Cette résolution est généralement exprimée en pixels par pouce ou ppp.
Le pouce est une unité anglo-saxonne : 1pouce = 2,54cm.
On peut également l'exprimer en pixels par centimètre ou px.cm-1
Exercice :
Une image a été capturée en "12Mpx" au format 4:3 par mon appareil photo. Quelle sera sa définition ?
Corrigé
Un format 4:3 indique que si une image contient y pixels en hauteur, elle doit en avoir (4/3)*y en largeur.
Le nombre total de pixel 12MPx = 12×106 correspond au produit du nombre de pixels en largeur et en hauteur.
Exercice :
Un écran 24" dispose d'une définition "Full-HD", quelle est sa résolution ?
Corrigé
Une définition "Full-HD" correspond à 1920pixels×1080pixels
La taille d'un écran correspond à sa diagonale

Comme la hauteur et la largeur de l'écran sont proportionnelles au nombre de pixels, considérés comme carrés, si y est la hauteur de l'écran en pouces, alors la largeur de l'écran vaut .
On peut appliquer le théorème de Pythagore entre la diagonale et les deux côté de l'écran, ce qui donne :
Si la hauteur est de 11,8 pouces et que l'écran a 1080 pixels en hauteurs, on a donc une résolution de:
Exercice :
Un écran au standard a une définition de px par __px.
Quel est son format ?
4/3
16/9
Autre
Exercice :
Un écran au format a une diagonale de pouces.
→ Il a une hauteur de cm et une largeur de cm.
Exercice :
Un écran au format a une diagonale de pouces.
Il a une définition de px en largeur par px en hauteur.
→ Sa résolution est de ppp.
II - Comparaison avec l'oeil⚓︎
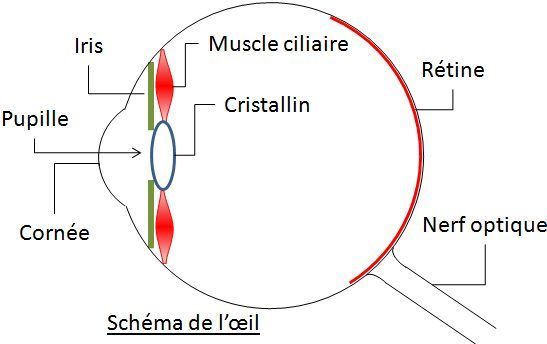
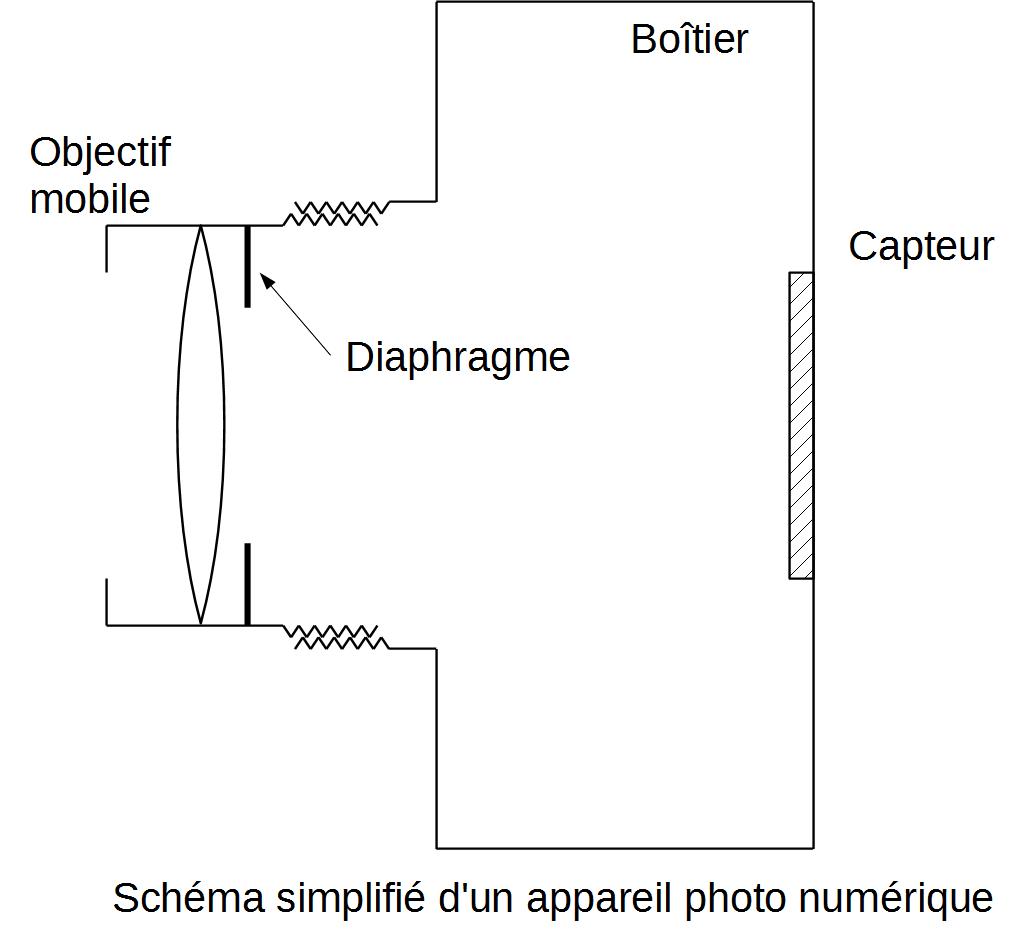
L'oeil et un dipositif de capture numérique partagent des structures similaires:
 |
 |
- L'image d'un objet se forme dans l'oeil sur la rétine qui se charge de transformer la lumière qu'elle reçoit en influx nerveux transmis via le nerf optique jusqu'au cerveau.
- Le capteur d'un appareil numérique fait la même chose en convertissant la lumière en signal numérique que l'ordinateur se chargera de traiter. L'équivalent du nerf optique pourrait être le câble USB qui relie la webcam à l'ordinateur.
- Pour que l'image se forme sur le capteur ou la rétine, il faut que la lumière issue de l'objet traverse une lentille qui fera converger les rayons de lumière. L'oeil contient un cristallin qui en contractant permettra de former l'image sur la rétine, que l'objet soit proche ou lointain. On appelle ce mécanisme l'accomodation.
- Dans un appareil photo, la lentille est en verre et ne peut donc pas se déformer. On choisit donc de déplacer la lentille d'avant en arrière pour faire la mise au point.
- Dans la rétine des cellules spécialisées, appelées cônes et bâtonnets convertissent la lumière en signaux électro-chimiques. Leur répartition sur la rétine n'est pas homogène, les cônes étant principalement présents au centre de la rétine tandis que les bâtonnets sont plutôt en périphérie.
Le capteur d'un appareil photo est au contraire une grille composée de photosites qui mesurent la quantité de lumière qu'ils reçoivent et transmettent l'information à l'ordinateur. - La pupille permet de limiter la lumière entrant dans l'oeil afin de ne pas être ébloui.
Sur les appareils photo type "reflex" un dispositif similaire appelé diaphragme peut être présent, mais généralement, c'est la durée pendant laquelle le capteur enregistre l'image qui va varier. Très courte en pleine lumière, elle peut être beaucoup plus longue en lumière faible, ce qui explique qu'il est plus difficile d'obtenir un photo nette la nuit : vos mouvements involontaire font davantage bouger l'appareil !
III - Définition⚓︎
La qualité de l'image qui va être capturée par le capteur de votre appareil photo dépend du nombre de photosites présents. Chaque photosite se contente de faire la moyenne des rayons de lumière qui le touchent. Ainsi plus le capteur comptera de photosites et mieux l'image sera définie
 Objet pris en photo |
 Image capturée avec un capteur disposant de 16 pixels |
Les capteurs actuels, présents sur les téléphones portables comptent généralement environ 20 millions de pixels.
Pixellisez une photo !⚓︎
Le code ci-dessous va vous permettre de pixelliser l'image de votre choix. Copiez-le dans le logiciel edupython, puis lancez la commande pixellise(64) où 64 représente le nombre de pixels que fera l'image dans sa plus grande dimension. Vous pouvez bien sûr mettre des valeurs plus petites ou plus grandes (mais il est inutile de dépasser 500, vous ne verrez plus la différence).
Le programme en se lançant vous demandera de choisir l'image de votre choix dans votre ordinateur.
Afficher le code
# -*- coding: utf-8 -*-
from PIL import Image
from tkinter import filedialog,Tk
def fichier(action):
popup=Tk()
if action=="ouvrir":
chemin_fichier = filedialog.askopenfilename(initialdir = "./",title = "Choisissez votre fichier")
elif action=="enregistrer":
chemin_fichier = filedialog.asksaveasfilename(initialdir = "./",title = "Nom du fichier à enregistrer")
else:
chemin_fichier=False
popup.destroy()
return chemin_fichier
def pixellise(res):
chemin_fichier = fichier("ouvrir")
image=Image.open(chemin_fichier)
(largeur,hauteur)=image.size
pix_max=max(largeur,hauteur)
pas=pix_max//res
largeur_finale,hauteur_finale=int((largeur//pas)*pas),int((hauteur//pas)*pas)
imagearrivee=Image.new('RGB',(largeur_finale,hauteur_finale))
if pas==0:
return False
for y in range(int(hauteur_finale/pas)):
for x in range(int(largeur_finale/pas)):
couleur=[0,0,0]
for a in range(pas):
for b in range(pas):
pixel=image.getpixel((x*pas+a,y*pas+b))
couleur[0],couleur[1],couleur[2]=couleur[0]+pixel[0],couleur[1]+pixel[1],couleur[2]+pixel[2]
couleur[0],couleur[1],couleur[2]=couleur[0]//pas**2,couleur[1]//pas**2,couleur[2]//pas**2
couleur=(couleur[0],couleur[1],couleur[2])
imagearrivee=dessine_carre(imagearrivee,x*pas,y*pas,pas,couleur)
imagearrivee.save(fichier("enregistrer"))
imagearrivee.show()
return True
def dessine_carre(image,x_top,y_top,cote,couleur):
for x in range(x_top,x_top+cote):
for y in range(y_top,y_top+cote):
image.putpixel((x,y),couleur)
return image
pixellise(64)
Afficher le code avec les commentaires
from PIL import Image
import tkinter as tk
from tkinter import filedialog
def pixellise(res):
#On utilise le module tkinter pour ouvrir une fenêtre
#afin de sélectionner le fichier à traiter.
#Le chemin de ce fichier est enregistré dans chemin_fichier
popup=tk.Tk()
chemin_fichier = filedialog.askopenfilename(initialdir = "./",title = "Select file",filetypes = (("Images","*.bmp *.jpg"),("all files","*.*")))
popup.destroy()
image=Image.open(chemin_fichier)
#On récupère les dimensions de l'image
(largeur,hauteur)=image.size
#On détermine quelle est la plus grande dimension : longueur ou largeur
pix_max=max(largeur,hauteur)
#On détermine le 'pas' de l'image pixellisée, c'est à dire à combien de pixels
#de l'image de départ correspondra un pixel de l'image d'arrivée
pas=pix_max//res
largeur_finale,hauteur_finale=int((largeur//pas)*pas),int((hauteur//pas)*pas)
#On crée une image vide aux dimensions de l'image d'origine
imagearrivee=Image.new('RGB',(largeur_finale,hauteur_finale))
#Si jamais on a donné un nombre de pixels supérieur à la résolution decode
#l'image d'origine, le programme s'arrête et renvoie la valeur "Faux"
if pas==0:
return False
#On va prendre successivement dans l'image des carrés contenant "pas" pixels en hauteur et en largeur
#On va ensuite faire la moyenne des couleurs sur chaque composante rouge, vert, bleu
for y in range(int(hauteur_finale/pas)):
for x in range(int(largeur_finale/pas)):
couleur=[0,0,0]
for a in range(pas):
for b in range(pas):
pixel=image.getpixel((x*pas+a,y*pas+b))
couleur[0],couleur[1],couleur[2]=couleur[0]+pixel[0],couleur[1]+pixel[1],couleur[2]+pixel[2]
couleur[0],couleur[1],couleur[2]=couleur[0]//pas**2,couleur[1]//pas**2,couleur[2]//pas**2
couleur=(couleur[0],couleur[1],couleur[2])
#Dans l'image finale, on dessine un carré de "pas" pixels en long et en large de la couleur moyenne que l'on vient de calculer
imagearrivee=dessine_carre(imagearrivee,x*pas,y*pas,pas,couleur)
#On enregistre l'image traitée
imagearrivee.save("image"+str(res)+".jpg")
#On affiche l'image
imagearrivee.show()
return True
#cette fonction dessine un carré dans une image, de la couleur indiquée
def dessine_carre(image,x_top,y_top,cote,couleur):
for x in range(x_top,x_top+cote):
for y in range(y_top,y_top+cote):
image.putpixel((x,y),couleur)
return image
IV - Couleurs⚓︎
1) Le pixel⚓︎
La couleur est une notion moins simple qu'il n'y paraît. Ce n'est pas une grandeur physique, mais une sensation, liée notamment à la façon dont notre oeil perçoit les images. De jour, lorsque la lumière est suffisante, ce sont nos cônes qui fonctionnent. Notre oeil est trichromate et dispose de 3 types de cônes : ceux sensibles au "rouge", ceux sensibles au "bleu" et ceux sensibles au "vert", couleur à laquelle notre oeil est le plus sensible.
Toutes les autres couleurs couleurs correspondent au mélange des stimulis de ces 3 cônes.
Les photosites des appareils photo sont sensibles de façon similaire à toute la plage visible (et un peu plus) de la lumière. Pour leur faire différencier les couleurs, on placera devant chaque photosite un filtre de couleur différente (rouge, vert ou bleu). C'est l'alliance d'un photosite rouge, d'un photosite bleu et d'un photosite vert qui formera un pixel de l'image numérisée.
2) Profondeur de couleur⚓︎
Comment faire représenter une couleur ? On va simplement la coder en binaire.
La profondeur de couleur correspond au nombre de couleurs différentes que va être capable de coder l'image et dépend du nombre de bits utilisés pour coder chaque composante, rouge, verte ou bleue.
Actuellement, chaque composante est notée sur 8 bits. On peut donc représenter 28=256 niveaux de chaque composante et 28 × 3 = 224 soit environ 17 millions de couleurs différentes, ce qui est bien supérieur à ce qu'un oeil peut distinguer.
coder une couleur :
On va représenter chaque couleur par un triplet (R,V,B) où chaque valeur Rouge, Vert, Bleu sera comprise entre 0 (pas du tout) et 255 (maximum).
- Le rouge pur aura comme code (255,0,0). Un rouge sombre, une valeur plus faible, comme (128,0,0). De même pour le vert et le bleu
- Pour les couleurs composées, comme le jaune (255,255,0) , ou le cyan (0,255,255), on peut imaginer des mélanges de couleur.
- Le blanc correspond au triplet (255,255,255) et le noir au triplet (0,0,0).
A vous de jouer !
L'animation suivante vous permet de jouer sur des leviers afin d'ajuster la couleur de la tache centrale. Essayez d'obtenir du orange, du violet et du gris
V - Stocker une image⚓︎
Comme toutes les informations, une image stockée sur un ordinateur n'est qu'un ensemble de 0 et de 1. - Par exemple : 1111000001011101000001111
Mais la seule chaine binaire de l'information portée par chaque pixel ne suffit pas : il faut indiquer à la machine comment interpréter ces données. C'est le rôle de l'en-tête, qui indiquera les information nécessaires pour interpréter correctement le fichier.
Ainsi, l'en-tête accompagnant la chaîne binaire précédente et nécessaire pour la décoder est : - les dimensions de l'image : 5 pixels de large par 5 pixels de haut, - chaque pixel est soit noir (1) soit blanc (0), - les pixels sont lus de gauche à droite et de haut en bas.
Entrez le code binaire ci-dessous
Essayez de trouver le code nécessaire pour obtenir l'image suivante :

Evidemment dans le cas où l'image est en couleur, non seulement il va falloir le déclarer dans l'en-tête, mais il sera en plus nécessaire de coder chaque pixel sur 3 x 8bits : 1 pixel d'une image en couleur prend donc autant de place que le code nécessaire pour représenter le "2" de l'image précédente !
On comprend alors qu'il va falloir recourir à un langage de programmation pour traiter l'image à notre place...
VI - Transformer une image⚓︎
Il est relativement simple de traiter une image avec python.
Par défaut, celui-ci sait ouvrir et lire un fichier : il sera capable d'afficher la suite de 1 et de 0 qui composent le fichier, mais il sera en revanche incapable de l'interpréter comme une image !
Il faudrait donc écrire un programme capable de le lui expliquer (comment lire l'en-tête, où trouver les informations donnant les dimensions de l'image, quels types de couleurs sont utilisées...). Heureusement, cela a déjà été fait : le module PIL est capable de nous aider.
>>> from PIL import Image
Il ouvrira et lira l'image demandée
>>> image=Image.open(chemin_fichier)
et sera capable de nous donner les informations nécessaires et la couleur de chaque pixel.
>>> largeur,hauteur=image.size
(1920, 1080)
Il peut aussi créer une image et nous aidera à réaliser les transformations que nous désirons.
1) Convertir une image en niveaux de gris⚓︎
On va utiliser une image quelconque (une photo prise par la caméra de votre ordinateur, mais cela peut être n'importe quoi d'autre), par exemple, celle-ci :

Si l'on regarde les informations de cette image, on voit que ses dimensions sont 1846 pixels de large et 1121 pixels de haut : cela représente plus de 2 millions de pixels.
L'opération de conversion va se faire sur chaque pixel de l'image, soit 2 millions de fois !
On va demander la couleur d'un pixel donné à PIL qui va nous retourner un code R,V,B où R sera la quantité de rouge, V celle de vert et B celle de bleu, toutes 3 comprises entre 0 et 255 (voir exemple ci-dessus) . Il faudra transformer cela en un nombre compris entre 0 et 255. L'idée la plus simple est de faire la moyenne des 3 valeurs RVB, en faisant attention à obtenir un nombre entier :
gris = int((rouge + vert + bleu)/255)
Il suffira ensuite d'écrire cette valeur dans l'image d'arrivée... pour chaque pixel de l'image.
On ne va évidemment pas écrire 2 millions de fois la même commande, mais faire appel aux boucles for.
On va d'abord lire l'image ligne par ligne, puis dans chaque ligne, pixel par pixel. Au final le programme ressemble à ça :
Voir le code
# -*- coding: utf-8 -*-
from PIL import Image
from tkinter import filedialog,Tk
# fonction permettant d'aller ouvrir ou enregistrer un fichier
def fichier(action):
popup=Tk()
if action=="ouvrir":
chemin_fichier = filedialog.askopenfilename(initialdir = "./",title = "Choisissez votre fichier")
elif action=="enregistrer":
chemin_fichier = filedialog.asksaveasfilename(initialdir = "./",title = "Nom du fichier à enregistrer")
else:
chemin_fichier=False
popup.destroy()
return chemin_fichier
def conversion_gris():
# On va faire apparaître une fenêtre qui permettra d'aller simplement
# chercher une image sur l'ordinateur
chemin_fichier = fichier("ouvrir")
# PIL ouvre maintenant l'image située dans le chemin qu'on a choisi
image=Image.open(chemin_fichier)
# On récupère les dimensions de l'image d'origine
(largeur,hauteur)=image.size
# On crée une image vide qui sera notre image finale
# Elle a les mêmes dimensions que l'image d'origine,
# PIL définit plusieurs types d'images, parmi elles
# Le noir ou blanc est noté "1", les niveaux de gris est noté "L" et les couleurs "RGB"
# notre image d'arrivée étant en niveaux de gris, on choisit "L"
imagearrivee=Image.new('L',(largeur,hauteur))
# On va appliquer la transformation à chaque ligne de l'image...
for ligne in range(hauteur):
# et à chaque pixel de chaque ligne
for pixel in range(largeur):
# On applique la transformation au pixel ayant pour coordonnée (pixel,ligne)
# On récupère la couleur de l'image de départ, sous la forme (R,V,B)
couleur = image.getpixel((pixel,ligne))
# on fait la moyenne des composantes
gris = int((couleur[0] + couleur[1] + couleur[2]) / 3)
# on écrit le résultat dans l'image d'arrivée
imagearrivee.putpixel((pixel, ligne), gris)
# le traitement est terminé. Il faut maintenant sauvegarder l'image et l'afficher
imagearrivee.save(fichier("enregistrer"))
imagearrivee.show()
return True
# Pour que la fonction se lance seule, on l'appelle
conversion_gris()
Et le résultat est :

Remarque : En réalité la conversion d'une image en couleur en niveaux de gris n'est pas une simple moyenne. En effet, notre oeil est plus sensible aux couleurs vertes : cette composante doit donc être traitée avec un coefficient plus important que le rouge et le bleu.
La norme en vigueur recommande plutôt l'opération suivante : Gris = 0.299 Rouge + 0.587 Vert + 0.114 Bleu
Essayez de modifier le programme pour prendre en compte cette recommandation !
VII - Les données EXIF⚓︎
En plus des informations nécessaires à la lecture de l'image, les fichiers image (jpg ou tiff mais pas png) incluent également des informations supplémentaires sur le dispositif qui a enregistré la photo. Ces informations peuvent être de divers ordres : la marque et le type d'appareil, les paramètres de l'appareil photo (durée de prise de vue, sensibilité, focale...) mais également l'heure et la date de prise de vue ou encore les coordonnées GPS de l'appareil au moment où la photo a été prise.
Le module PIL que l'on a utilisé pour traiter les images est capable d'extraire les données EXIF.
Le code suivant va vous demander de choisir une image et affichera les informations contenues dans la balise EXIF de l'image que vous avez sélectionnée
Montrer le code
from PIL import Image
import tkinter as tk
from tkinter import filedialog
def exif():
popup=tk.Tk()
chemin_fichier = filedialog.askopenfilename(initialdir = "./",title = "Select file",filetypes = (("Images","*.jpg"),("all files","*.*")))
popup.destroy()
image=Image.open(chemin_fichier)
donnees=image._getexif()
print(donnees)
exif()
En appliquant ce code sur l'image suivante :

On visualise cela :
Résultat
>>> exif()
{256: 3968, 257: 2976, 258: (8, 8, 8), 36864: b'0210', 37121: b'\x01\x02\x03\x00', 37377: (298973, 10000), 36867: '2019:12:13 11:10:38', 36868: '2019:12:13 11:10:38', 37378: (227, 100), 37379: (0, 1), 37380: (0, 10), 41995: b'ipp\x00', 37383: 5, 37384: 1, 270: 'sdr', 271: 'HUAWEI', 272: 'BLL-L22', 37385: 24, 274: 0, 531: 1, 40962: 3968, 37520: '962209', 37521: '962209', 37522: '962209', 40963: 2976, 41495: 2, 282: (72, 1), 283: (72, 1), 40965: 8424, 41728: b'\x03', 33434: (1255000, 1000000000), 33437: (220, 100), 41729: b'\x01', 34850: 2, 34853: {0: b'\x02\x02\x00\x00', 1: 'N', 2: ((43, 1), (40, 1), (28431701, 1000000)), 3: 'E', 4: ((4, 1), (6, 1), (32423057, 1000000)), 5: b'\x01', 6: (0, 100), 7: ((10, 1), (10, 1), (36, 1)), 27: b'CELLID\x00', 29: '2019:12:13'}, 41985: 1, 34855: 50, 296: 2, 41986: 0, 40960: b'0100', 41987: 0, 305: 'BLL-L22C636B396', 306: '2019:12:13 11:10:38', 41988: (100, 100), 41989: 26, 41990: 0, 37386: (3830, 1000), 41991: 0, 40961: 1, 41992: 0, 41993: 0, 41994: 0, 41996: 0, 34665: 280, 37500: b'Auto\x00'}
Que signifie cette sortie ?
On remarque déjà que les résultats sont entre accolades : il s'agit d'un type de variable appelé dictionnaire : semblable à une liste, sauf que l'indice est remplacé par une étiquette.
L'avantage, on le voit sur les 4 premières sorties : 256: 3968, 257: 2976, 258: (8, 8, 8), 36864: b'0210' → on passe de l'étiquette 258 à l'étiquette 36864 et les étiquettes intermédiaires n'existent pas. Cela aurait été impossible avec une liste. De plus les étiquettes peuvent également être des chaînes de caractère.
Certaines valeurs sont incompréhensibles, mais par exemple 36867: '2019:12:13 11:10:38' semble clairement être une date, 271: 'HUAWEI' fait apparaître une marque connue de téléphone, on en déduit que 272: 'BLL-L22' qui vient juste derrière est probablement le numéro du modèle.
Pas besoin de se fatiguer, la signification de chaque clé est expliquée ici http://www.exiv2.org/tags.html.
Les 3 étiquettes 256,257,258 indiquent la définition de l'image telle qu'elle a été prise (je l'ai redimensionnée à 1024px de large, mais cela n'a pas été précisé par le logiciel que j'ai utilisé pour redimensionner l'image) ainsi que la profondeur de couleur.
Sont également présentes des informations sur les paramètres de l'appareil photo, telles que la sensibilité ISO (34855), la focale, la durée de prise de vue ...
Ce qui nous intéresse dans notre cas, c'est l'étiquette 34853 : elle indique des coordonnées GPS.
On peut lire dans cette étiquette que les coordonnées sont 43°40'28.431701" Nord et 4°06'32,423057" Est
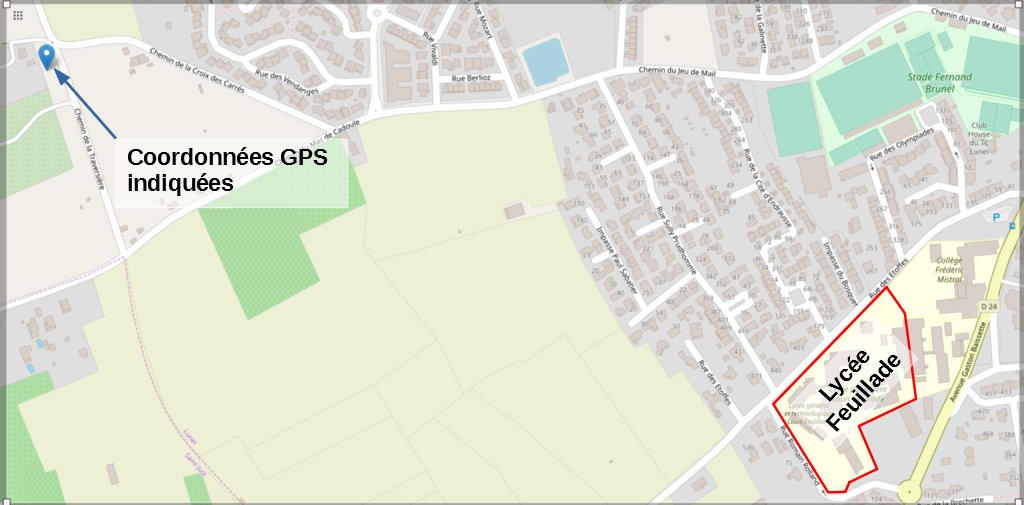
Comme la photo a manifestement été prise du lycée, pourquoi les coordonnées ne sont pas les bonnes ?
Par défaut, lorsque le signal GPS n'est pas disponible, comme ce peut être le cas lorsque la photo est prise en intérieur, un smartphone indiquera dans l'étiquette les coordonnées de l'antenne téléphonique à laquelle il est connecté !
VIII - Les types de fichiers image⚓︎
La photo précédente a une définition de 1024px × 768px, avec une profondeur de couleurs de 24bits.
Cela signifie donc que l'espace occupé en théorie par cette image est de \(1024 \times 768 \times 24 = 18.874.368 bits = 2.358.296 octets\), or le fichier a une taille de 274.440 octets, presque 10 fois moins !
Remarque
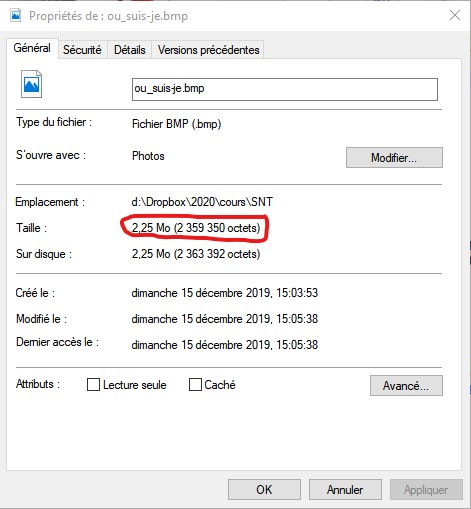
Ce que vous verrez si vous téléchargez l'image au format bitmap et que vous faites un clic droit dessus, puis "propriétés" sous Windows.
{kind=link}
Windows indique une taille correcte en octets, mais celle en Mégaoctets semble inférieur !
Historiquement les informaticiens n'ont pas choisi les multiples k = 1 000 M = 1 000 000... mais des valeurs proches k = 210=1 024, M=220=1 048 576, qui sont des puissances de 2, faciles à coder en binaire.
En 1998, la norme imposant à l'informatique de respecter les multiples du système international est entrée en vigueur. Le "kilo" informatique s'appelle désormais "kibi".
Si vous divisez 2 359 296 par 1 048 576 vous trouverez effectivement 2.25.
Windows ne respecte donc pas la norme internationale et devrait afficher 2,25Mio (2.25 Mibioctets) et non pas 2,25Mo.
Compte-tenu du nombre d'informations que contient une image, celles-ci sont généralement très lourdes. On va donc avoir tendance à les compresser.
A savoir
Il existe 2 façons de compresser une image : - A l'image d'un fichier zip, l'image va être compressée, tout en conservant toutes les informations d'origine. Il est ainsi possible de retrouver l'image d'origine exacte. Dans cette catégorie, vous trouverez le format TIFF, mais surtout PNG, qui est un standard sur internet lorsqu'une image doit rester fidèle à l'originale. Dans ce format, le poids de la photo descend à 1 407 311 octets, ce qui représente un gain de 40%.
- <u>Inconvénient :</u> le format png ne préserve pas les données EXIF de l'image.
-
A l'image d'un fichier mp3, l'image va non seulement être compressée, mais on va en plus prendre en compte les spécificités de la sensibilité de l'oeil humain pour enlever les informations non pertinentes. Dans cette catégorie, vous trouverez essentiellement le format JPEG. Dans ce format (avec un réglage à 85% de qualité) le poids de la photo descend à 274 440octets, soit une baisse de 88% !
- Inconvénient : cette forte baisse du poids se fait au détriment de la qualité, il n'est plus possible de restituer l'image originale et des artefacts apparaissent sur l'image
On récapitule :
- Je veux une image identique à celle capturée dans laquelle je peux accéder directement à toutes les valeurs de chaque pixel ⇒ BMP
- Je veux une image identique à l'originale, mais en ayant le poids le plus faible possible ⇒ PNG
- Je veux une image de qualité correcte, mais en ayant le poids le plus faible possible ⇒ JPEG
Extrait du BO
Introduction⚓︎
Les technologies de la photographie argentique ont eu une évolution très lente, liée aux progrès en optique, mécanique et chimie. Ce n’est plus du tout le cas de l’évolution actuelle, davantage due aux algorithmes qu’à la physique : algorithmes de développement et d’amélioration de l’image brute, algorithmes d’aide à la prise de vue. Cet exemple est caractéristique des façons de procéder de la révolution informatique par rapport aux approches traditionnelles.
La photographie numérique présente un coût marginal très faible et une diffusion par internet facile et immédiate : chaque jour, des milliards de photos sont prises et partagées.
Repères historiques⚓︎
- 1826 : naissance de la photographie argentique
- 1900 : photographie en couleurs. Après la seconde guerre mondiale, généralisation du format 24 x 36 et de la visée reflex
- 1969 : arrivée des premiers capteurs CCD (Charge Coupled Device)
- 1975 : apparition des premiers appareils numériques
- 2007 : arrivée du smartphone.
Les données et l’information⚓︎
En entrée, le capteur est formé de photosites en matrice de petits carrés de quatre photosites, deux verts, un bleu et un rouge, correspondant à la répartition des cônes de la rétine. La résolution du capteur se mesure en millions de photosites. En sortie, l’image est formée de pixels colorés homogènes, représentés par trois nombres RVB (rouge, vert, bleu). La résolution de l’image se compte en mégapixels, elle n’est pas forcément égale à celle du capteur. La profondeur de couleur est en général de 8 bits par pixel et par couleur pour l’image finale.
Des métadonnées sont stockées dans les fichiers images sous format EXIF (Exchangeable Image File Format) : modèle de l’appareil, objectif, vitesse, diaphragme, distance de mise au point, auteur, copyright, localisation, etc.
Les couleurs peuvent être représentées dans différents systèmes : RVB, TSL (teinte, saturation, lumière), avec des formules empiriques de passage d’un modèle à l’autre. On distingue différents formats des fichiers images, compressés ou non, avec ou sans perte : RAW, BMP, TIFF, JPEG.
Les algorithmes et les programmes⚓︎
Des algorithmes permettent de traiter toutes les lumières, d’effectuer une retouche facile, avec une qualité maintenant bien supérieure à l’argentique. Avec l’arrivée du téléphone mobile, des algorithmes de fusion d’images permettent de concilier une excellente qualité avec un capteur et un objectif minuscules.
De nombreux algorithmes sophistiqués sont utilisés dans les appareils de photographie numérique : - Lors de la prise de vue : calcul de l’exposition, mise au point, stabilisation par le capteur et/ou l’objectif, le tout en automatique ou manuel assisté, focus-peaking (scintillement des contours nets), prise en rafales rapides d’images multiples avant et après appui sur le déclencheur. - Lors du développement de l’image issue du capteur en une image pixellisée : gestion de la lumière et du contraste, balance des blancs, netteté, débouchage des ombres, correction automatique des distorsions ou des aberrations optiques. - Après le développement : compression du fichier (TIFF sans perte, JPEG avec perte). - En utilisant la fusion d’images : réduction du bruit et amélioration de la netteté, panoramas, HDR (High Dynamic Range), super-résolution par micro-décalages du capteur, focus stacking pour étendre la netteté avec plusieurs mises au point successives, réduction du bruit et amélioration de la netteté. - Certains appareils peuvent augmenter leurs fonctionnalités par téléchargement de nouveaux logiciels.
Les machines⚓︎
Comme les algorithmes de prise de vue et de développement demandent beaucoup de calcul, les appareils embarquent plusieurs processeurs, généraux ou spécialisés.
Les algorithmes prennent le relais des capteurs physiques en calculant les pixels de l’image finale : ils compensent par exemple les distorsions des lentilles. Des algorithmes permettent également de commander la mise au point et l’exposition automatique, ainsi que de compenser le bougé de l’utilisateur (stabilisation).
Impacts sur les pratiques humaines⚓︎
La gratuité et l’immédiateté de la réplication des images introduisent de nouveaux usages de la photographie : à la photographie archive (histoire de famille) s’ajoutent la photographie à partager et la photographie utilitaire, prothèse de la mémoire (photo d’un ticket de caisse, d’une présentation lors d’une réunion de travail, d’une place de parking, etc.). Les images s’intègrent à tous les dispositifs de communication et de partage, téléphones, Web et réseaux sociaux.
De nouveaux problèmes apparaissent, liés à la diffusion de photos qui ne disparaîtront jamais (notion de droit à l’oubli), au trucage difficile à détecter des images, au pistage des individus ou à l’obsolescence des supports. Est ainsi posée la question de l’archivage de photographies historiques, scientifiques ou culturelles.